Gérer les problèmes courants en JavaScript
Dans cet article, nous verrons certains problèmes fréquents qui se posent entre les différents navigateurs avec JavaScript, et aussi comment les résoudre.
Pour cela, nous aborderons entre autres les outils de développement des navigateurs pour diagnostiquer et corriger les problèmes, les prothèses d'émulation (ou polyfills) et les bibliothèques pour contourner les problèmes en parvenant à faire fonctionner des fonctionnalités JavaScript récentes dans d'anciens navigateurs.
| Prérequis : | Connaissance des bases de HTML, CSS, et JavaScript. Une idée générale des principes de tests entre les différents navigateurs. |
|---|---|
| Objectifs : | Être capable de diagnostiquer les problèmes fréquents, causés par JavaScript, entre les différents navigateurs et utiliser les techniques et outils appropriés pour les résoudre. |
Le problème avec JavaScript
Par le passé, JavaScript était la source de nombreux problèmes de compatibilité entre les différents navigateurs. Dans les années 1990, les navigateurs principaux existants alors (Internet Explorer et Netscape) n'implémentaient pas les scripts avec exactement le même langage (Netscape utilisait JavaScript, et IE utilisait JScript en permettant aussi d'utiliser VBScript). Bien que JavaScript et JScript étaient compatibles à un certain niveau (les deux étaient basés sur la spécification ECMAScript), la plupart des choses étaient implémentées de façon incompatible et conflictuelle, entraînant des nœuds au cerveau lorsqu'il fallait développer un site web compatible.
De tels problèmes ont subsisté jusqu'aux débuts des années 2000, où ces anciens navigateurs étaient alors encore utilisés et où il fallait continuer de les prendre en charge. Par exemple, dans du code utilisé pour créer un objet XMLHttpRequest, il fallait gérer le cas particulier d'Internet Explorer 6 :
if (window.XMLHttpRequest) {
// Mozilla, Safari, IE7+…
httpRequest = new XMLHttpRequest();
} else if (window.ActiveXObject) {
// IE 6 et les versions antérieures
httpRequest = new ActiveXObject("Microsoft.XMLHTTP");
}
C'est l'une des raisons pour lesquelles des bibliothèques comme jQuery sont apparues : permettre de gommer les différences d'implémentation entre les navigateurs afin de pouvoir utiliser une fonction comme jQuery.ajax(), qui gèrerait ces différences en arrière-plan.
La situation s'est grandement améliorée depuis. Les navigateurs modernes ont une bonne compatibilité concernant les fonctionnalités JavaScript classiques, et les contraintes où il fallait prendre en charge les anciens navigateurs se sont allégés (ceux-ci étant beaucoup moins utilisés, mais toujours existants).
De nos jours, les problèmes de compatibilité JavaScript entre les différents navigateurs se posent lorsque :
- Du code de piètre qualité essayant de déterminer le navigateur utilisé ou essayant de détecter certaines fonctionnalités, ou encore utilisant des préfixes propriétaires empêche les navigateurs d'exécuter du code qui aurait fonctionné correctement sinon.
- Des fonctionnalités très récemment ajoutées à JavaScript ou des API Web récentes sont présentes dans le code, et cela ne fonctionne pas pour les navigateurs plus anciens.
Nous verrons ces différents problèmes, ainsi que d'autres, par la suite.
Résolution générale des problèmes en JavaScript
Comme nous l'avons dit dans l'article précédent à propos de HTML et CSS, assurez vous que votre code fonctionne déjà normalement avant de vous concentrer sur les problèmes entre les navigateurs. Si vous n'avez pas lu l'article Diagnostiquer des problèmes JavaScript, nous vous invitons à le faire avant de poursuivre. En effet, identifier de nombreux problèmes rencontrés avec JavaScript comme ceux-ci pourra vous aider à mieux diagnostiquer un problème de compatibilité. Parmi les problèmes fréquents causés par JavaScript, on a :
-
Les problèmes de syntaxe et de logique de base (voir Diagnostiquer des problèmes JavaScript).
-
La gestion des portées pour la définition des variables : s'assurer qu'il n'y a pas de conflits entre les différentes valeurs déclarées à différents endroits (Voir Portée d'une fonction et conflits).
-
La confusion à propos de
this, la portée à laquelle il s'applique, pouvant changer la valeur à laquelle on s'attend. Vous pouvez lire Qu'est-ce que « this » ? comme introduction à ce sujet, et aussi étudier quelques exemples comme celui-ci, qui illustre un usage classique où on enregistre la valeur dethispour une portée donnée dans une variable séparée afin de l'utiliser dans des fonctions imbriquées, pour être sûr·e d'appliquer le code au bonthis. -
L'usage incorrect de fonctions au sein de boucles qui utilisent une variable globale (ce qui correspond plus généralement à une confusion sur les portées). Par exemple, dans
bad-for-loop.html(voir le code source), on exécute 10 itérations en utilisant une variable définie avecvar, en créant à chaque fois un paragraphe auquel on attache un gestionnaire d'évènementonclick. Lorsqu'on clique sur les paragraphes, on souhaite afficher un message d'alerte indiquant le numéro du paragraphe (c'est-à-dire la valeur deiau moment où le paragraphe a été ajouté). Au lieu de ce résultat, tous les messages d'alertes affichent la valeur 11, car la bouclefora terminé ses itérations avant que les fonctions imbriquées soient appelées.Note : La solution la plus simple consiste à déclarer la variable d'itération avec
letplutôt quevarpour que la valeuriassociée à chaque fonction soit unique pour chaque itération. Malheureusement, cela ne fonctionne pas avec IE11, et c'est pourquoi nous n'avons pas utilisé cette solution pour la version correcte de cet exemple.Pour que cela fonctionne, il faut définir séparément une fonction à attacher aux gestionnaires, et l'appeler à chaque itération en lui passant la valeur courante pour
paraeti. Voir le fichiergood-for-loop.html(et le code source correspondant) pour une version fonctionnelle. -
Tenter d'utiliser des résultats d'opérations asynchrones non terminées. Il faudra par exemple s'assurer qu'une requête est bien terminée et qu'elle a fourni une réponse avant de vouloir utiliser la réponse en quesiton. L'ajout des promesses en JavaScript a permis de simplifier ce problème.
Outils d'analyse de code (linters)
Comme pour HTML et CSS, vous pouvez vous aider d'un linter pour écrire du JavaScript de meilleure qualité. Un tel outil vous indiquera certaines erreurs et pourra aussi émettre des avertissements quant à des mauvaises pratiques. Vous pourrez le paramétrer pour qu'il soit plus ou moins strict. Nous vous recommandons particulièrement ESLint et nous verrons certains usages par la suite.
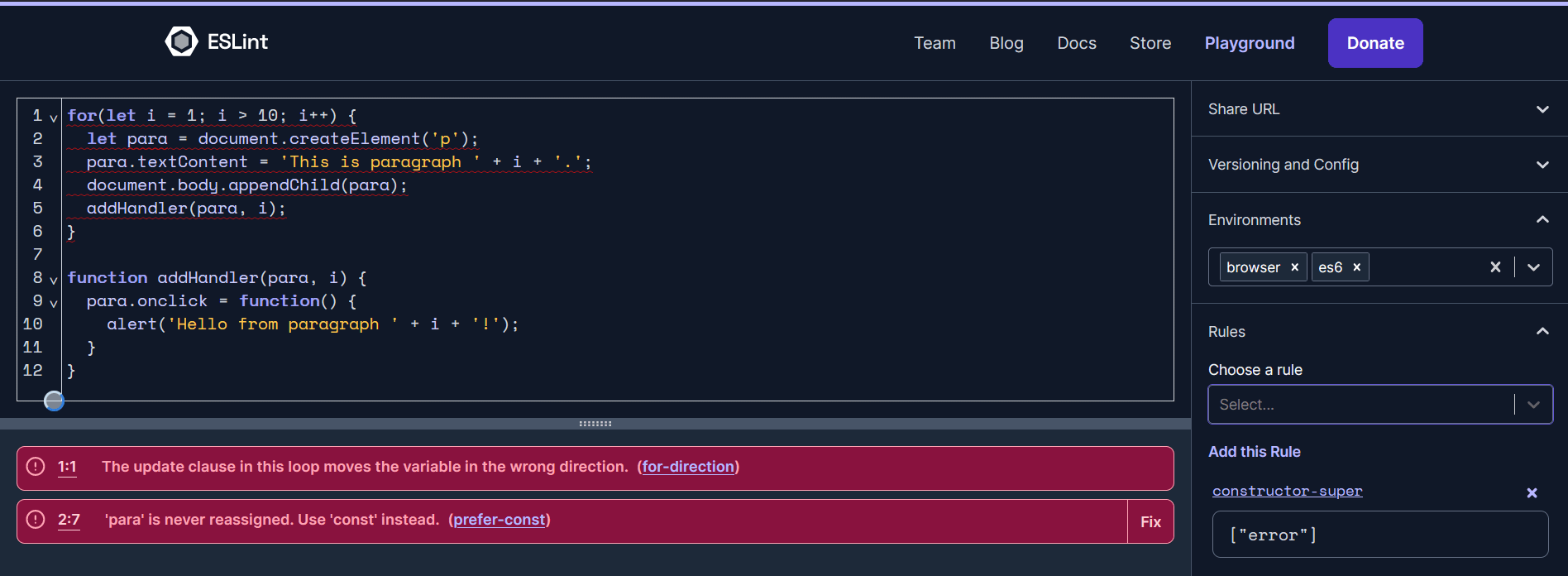
Utilisation en ligne
Le bac à sable ESLint permet de le tester dans un navigateur web en saisissant du code JavaScript dans le volet gauche. Dans la zone en dessous, vous pourrez voir les différentes erreurs et avertissement.
Extensions pour les éditeurs
Copier-coller du texte sur une page web n'est pas une option valable au quotidien. On veut qu'un tel outil soit bien intégré à l'éditeur de texte qu'on utilise. De nombreux IDE et éditeurs peuvent être configurés pour utiliser ces outils, voir la page sur les intégrations d'ESLint.
Autres cas d'usage
Il existe d'autres façons d'utiliser ces linters. Pour en savoir plus, référez vous à leur documentation (par exemple, la page pour démarrer avec ESLint (en anglais)).
On peut notamment utiliser ces outils avec la ligne de commande et les installer pour cet usage avec npm (Node Package Manager, qui nécessite d'avoir installé Node.js). La ligne de commande suivante permet d'installer ESLint :
npm install -g eslint
On peut alors utiliser la commande eslint dans un projet pour en analyser les fichiers.
Ces outils peuvent être utilisés avec les outils de compilation comme Gulp ou Webpack pour analyser automatiquement le code JavaScript lors du développement (voir comment Utiliser un agent pour automatiser les tests dans un article suivant). Voir la page sur les intégrations ESLint avec les outils de compilation.
Les outils de développement des navigateurs
Les outils de développement présents dans les navigateurs disposent de fonctionnalités utiles pour aider à déboguer du code JavaScript. La console JavaScript est un point de départ intéressant et permet de voir les erreurs à l'exécution.
Enregistrez une copie locale du code source de l'exemple broken-ajax.html, puis ouvrez le fichier HTML dans votre navigateur.
Si vous ouvrez la console, vous pourrez voir le message d'erreur "Uncaught TypeError: can't access property "length", heroes is undefined", et la référence à la ligne 49. Dans le fichier source, cela correspond à la section suivante :
function showHeroes(jsonObj) {
let heroes = jsonObj["members"];
for (const hero of heroes) {
// …
}
// …
}
On voit que le code échoue dès qu'on accède à une propriété de jsonObj (dont on s'attend à ce que ce soit un objet JSON). Cette valeur est normalement récupérée depuis un fichier JSON tiers à l'aide de l'appel XHR suivant :
let requestURL =
"https://mdn.github.io/learning-area/javascript/oojs/json/superheroes.json";
let request = new XMLHttpRequest();
request.open("GET", requestURL);
request.send();
let superHeroes = request.response;
populateHeader(superHeroes);
showHeroes(superHeroes);
Mais cela échoue.
L'API Console
Vous savez peut-être déjà ce qui cloche, mais voyons comment investiguer. Pour commencer, nous disposons de l'API Console qui permet à du code JavaScript d'interagir avec la console JavaScript du navigateur. Cette API possède différentes fonctionnalités, mais nous allons ici utiliser console.log() qui permet d'afficher un message personnalisé dans la console.
Insérez la ligne suivante juste après la ligne 31 :
console.log("Valeur de la réponse : ", superHeroes);
Actualisez la page dans le navigateur et vous pourrez alors voir un message dans la console « Valeur de la réponse : », suivi du même message d'erreur qu'auparavant.
L'appel à console.log() nous permet de voir que l'objet superHeroes ne semble rien contenir. Nous avons ici un problème récurrent avec les requêtes asynchrones comme celle-ci, où nous essayons d'utiliser la réponse avant que celle-ci ait effectivement été envoyée sur le réseau. Corrigeons ce problème en exécutant le code après que l'évènement load a été déclenché. Retirez la ligne avec console.log(), et changez le fragment suivant :
const superHeroes = request.response;
populateHeader(superHeroes);
showHeroes(superHeroes);
En cette version :
request.onload = function () {
let superHeroes = request.response;
populateHeader(superHeroes);
showHeroes(superHeroes);
};
Pour résumer, lorsque quelque chose ne fonctionne pas et qu'une valeur n'est pas ce qu'elle devrait être à un endroit du code, vous pouvez utiliser console.log() pour l'afficher et analyser ce qui se passe.
Utiliser le débogueur JavaScript
Malheureusement, l'erreur est toujours là. Continuons notre enquête en utilisant un outil plus avancé : le débogueur JavaScript.
Note : Des outils équivalents sont disponibles dans les autres navigateurs : l'onglet Sources de Chrome et Edge, le débogueur de Safari (voir les outils de développement de Safari).
Dans Firefox, l'onglet du débogueur se présente ainsi :
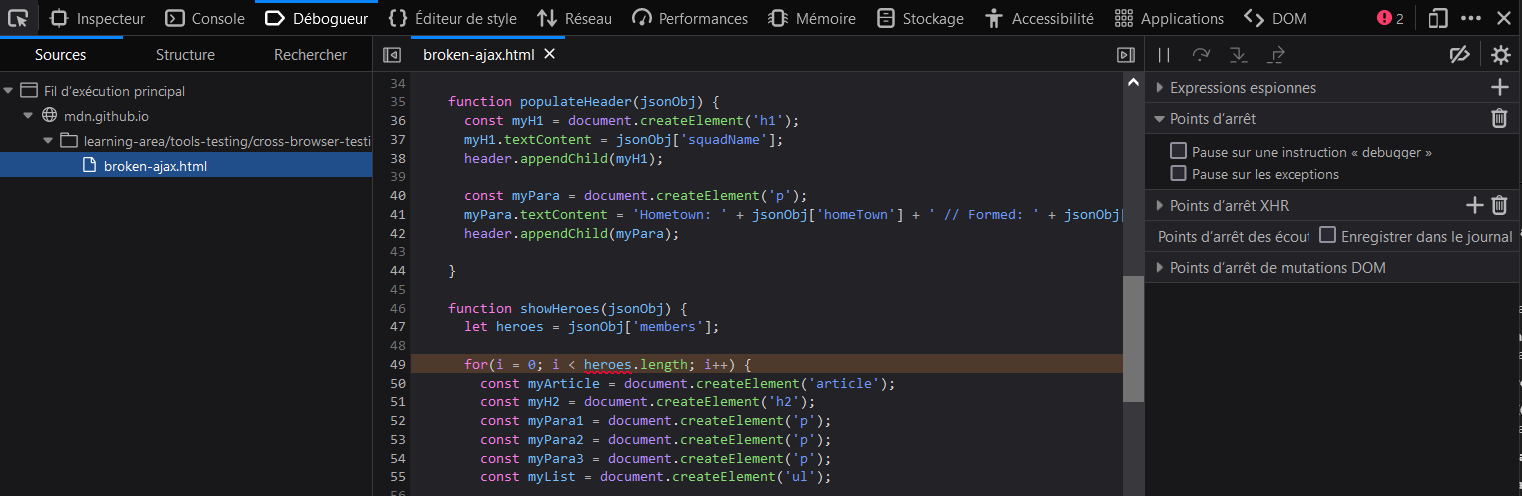
- Sur la gauche, on peut sélectionner le script qu'on souhaite déboguer (ici il n'y en a qu'un).
- Le panneau central affiche le code du script sélectionné.
- Le panneau à droite affiche différents détails à propos de l'environnement actuel (points d'arrêt, pile d'exécution, et portées actives entre autres).
La fonctionnalité principale du débogueur est la possibilité d'ajouter des points d'arrêt dans le code. Il s'agit de points où le code s'arrêtera et où on pourra examiner l'environnement dans son état actuel, pour étudier ce qui se passe, avant de reprendre la suite de l'exécution.
Exploitons donc cet outil. L'erreur se produit désormais à la ligne 49. Cliquez sur la ligne 49 dans le panneau central pour ajouter un point d'arrêt (vous verrez une flèche bleue apparaître à gauche). Actualisez ensuite la page (Cmd/Ctrl + R) et le navigateur suspendra l'exécution à la ligne 49. Le panneau à droite affichera alors plusieurs informations utiles.
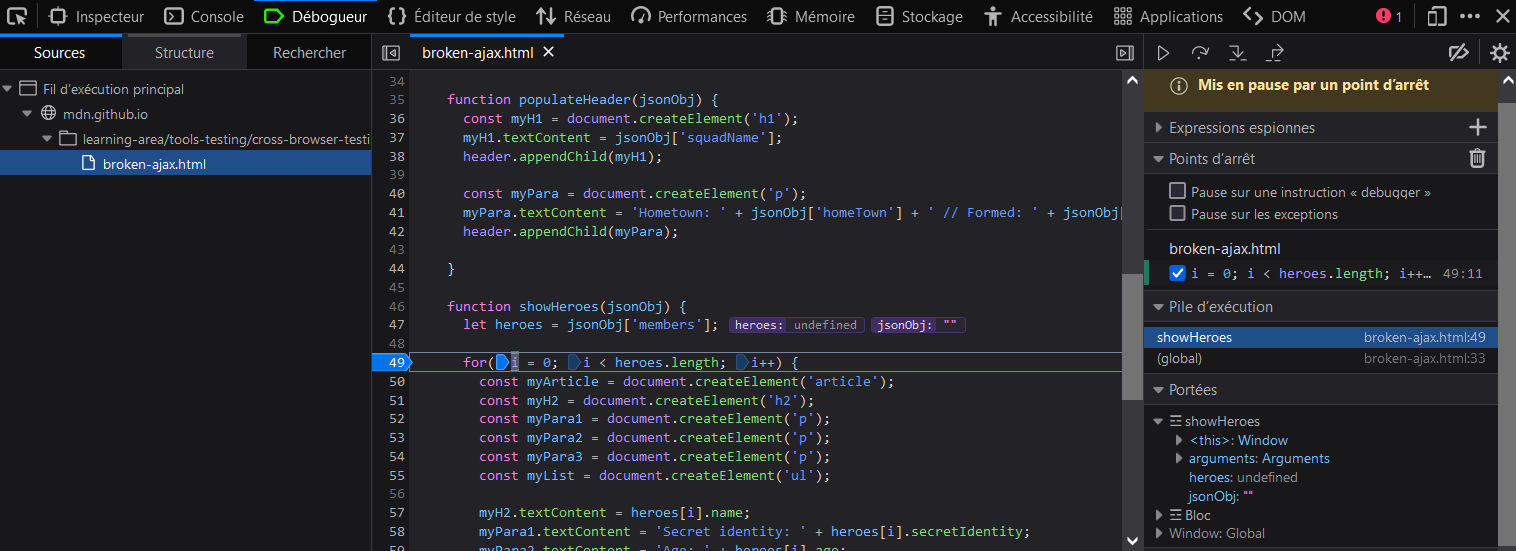
- Dans la section Points d'arrêt, vous pouvez voir les détails sur le point d'arrêt que vous avez placé.
- Sous Pile d'exécution, vous pouvez voir la liste des fonctions qui ont été appelées pour que la fonction courante soit appelée. En haut, nous avons
showHeroes(), qui est la fonction courante, et en dessous, nous avonsonload, qui correspond à la fonction de gestion d'évènement qui contient l'appel àshowHeroes(). - Sous Portées, vous pouvez voir la portée active de la fonction que nous regardons. Il y a ici trois portées :
showHeroes, bloc, etWindow(la portée globale). Chaque portée peut être développée pour afficher les valeurs des variables à l'intérieur de la portée au moment où l'exécution a été suspendue.
Nous avons ici plusieurs informations très utiles.
- En dépliant la portée
showHeroes, on peut voir que la variableheroesvautundefined, ce qui indique que l'accès à la propriétémembersde l'objetjsonObj(la première ligne de la fonction) n'a pas fonctionné. - On peut aussi voir que la variable
jsonObjcontient une chaîne de caractères et pas un objet JSON. - En cliquant sur
onloaddans la section Pile d'exécution, on peut analyser ce qui s'est passé à l'appel de la fonction. La vue est alors mise à jour pour afficher la fonctionrequest.onloaddans le panneau central et sa portée dans la section Portées. - Si vous développez la portée
onload, vous pourrez voir que la variablesuperHeroesest également une chaîne de caractères et pas un objet. C'est là notre problème, l'appelXMLHttpRequestrenvoie du JSON sous forme de texte et pas sous forme d'un objet JSON.
Nous vous donnons ici l'occasion de corriger le problème par vous-même. Pour vous donner quelques pistes, vous pouvez paramétrer l'objet de la requête XMLHttpRequest pour recevoir explicitement une réponse au format JSON, ou convertir le texte obtenu en JSON après avoir reçu la réponse. Si vous coincez, vous pouvez consulter le code source de l'exemple corrigé.
Note : Le débogueur possède de nombreuses autres fonctionnalités que nous n'avons pas abordées ici, comme les points d'arrêt conditionnels et les expressions espionnes. Pour plus d'informations, référez vous à la documentation du débogueur Firefox.
Les problèmes de performance
Lorsqu'une application devient de plus en plus complexer et qu'on utilise de plus en plus de JavaScript, on pourra rencontrer des problèmes de performances, notamment sur les appareils les plus lents. L'optimisation des performances est un vaste sujet que nous ne pourrons couvrir entièrement dans cet article. Voici quelques conseils rapides :
- Pour éviter de charger plus de JavaScript que nécessaire, vous pouvez empaqueter vos scripts dans un seul fichier à l'aide d'un outil comme Browserify. De façon générale, réduire le nombre de requêtes HTTP permet d'améliorer les performances.
- Minifiez/compressez vos fichiers avant de les déployer sur votre serveur de production. La minification consiste à compresser l'ensemble du code sur une seule ligne et en renommant certaines des variables pour obtenir un fichier beaucoup plus petit. Le code obtenu est presqu'illisible, mais à ce moment, il est là pour être exécuté plutôt que lu.
terserest un exemple d'outil de minification. - Lorsque vous utilisez des API, assurez vous de désactiver les fonctionnalités que vous n'utilisez pas. Certains appels d'API ont un impact élevé sur les performances. Par exemple, lors de l'affichage d'un flux vidéo, assurez vous de l'arrêter lorsque la vidéo est hors de la zone d'affichage de la page. De même, si vous suivez la position géographique d'une personne à l'aide d'appels à l'API Geolocation, assurez vous d'arrêter les appels lorsque la personne n'utilise plus le site ou l'application.
- Les animations peuvent s'avérer coûteuses en performances. De nombreuses bibliothèques JavaScript fournissent des outils d'animation en JavaScript. Toutefois, il est plus efficace d'implémenter des animations avec des fonctionnalités natives comme les animations CSS ou l'API Web Animations.
Les problèmes de compatibilité entre navigateurs causés par JavaScript
Dans cette section, nous verrons certains des problèmes causés par JavaScript en ce qui concerne la compatibilité entre les navigateurs. Nous verrons :
- L'utilisation de fonctionnalités JavaScript récentes
- L'utilisation d'API Web récentes
- L'utilisation de mauvais code pour tenter d'identifier le navigateur
- Les problèmes de performance
Utilisation d'API Web ou de fonctionnalités JavaScript récentes
Dans l'article précédent, nous avons vu comment gérer certains problèmes liés aux fonctionnalités HTML ou CSS non prises en charge grâce à la nature de ces langages. Toutefois, JavaScript n'est pas aussi permissif que HTML et CSS, si le moteur JavaScript rencontre une erreur ou une syntaxe qu'il ne reconnait pas (par exemple lorsqu'une nouvelle fonctionnalité, pas encore prise en charge, est utilisée), il déclenchera une erreur.
Il existe différentes stratégies pour gérer la prise en charge des fonctionnalités récentes. Voyons-en quelques-unes.
Note : Ces stratégies ne s'excluent pas les unes les autres. Vous pouvez les combiner si besoin. Par exemple, vous pouvez utiliser la détection de fonctionnalité pour déterminer si une API est prise en charge, et si elle ne l'est pas, exécuter du code pour charger une bibliothèque ou une prothèse d'émulation pour palier ce manque.
Détection de fonctionnalité
L'idée de cette stratégie consiste à exécuter un test pour déterminer si une fonctionnalité JavaScript est prise en charge dans le navigateur courant, puis d'exécuter du code de façon conditionnelle afin de fournir un résultat acceptable dans les deux cas. Prenons un exemple rapide avec l'API Geolocation (qui expose les données d'emplacement géographique de l'appareil sur lequel le navigateur est exécuté), qui a un point d'entrée principal avec la propriété globale geolocation, disponible sur l'objet navigator. Pour détecter si le navigateur prend en charge la géolocalisation, on pourra écrire ceci :
if ("geolocation" in navigator) {
navigator.geolocation.getCurrentPosition((position) => {
// On affiche l'emplacement sur une carte, par exemple avec un fond de carte OpenStreetMap
// qui évolue en temps réel
});
} else {
// On utilise plutôt une carte statique à défaut
}
On pourra écrire un test analogue pour la prise en charge d'une fonctionnalité CSS, en testant l'existence de element.style.propriete (par exemple paragraph.style.transform !== undefined). Si vous souhaitez appliquer des styles selon la prise en charge d'une fonctionnalité CSS, vous pouvez directement utiliser la règle @ @supports. Ainsi, si on souhaite déterminer si le navigateur courant prend en charge les requêtes de conteneur, on pourra écrire :
@supports (container-type: inline-size) {
/* On utilise les requêtes de conteneur si elles sont prises en charge */
}
Attention, il ne faut pas confondre la détection de fonctionnalité avec la tentative d'identification du navigateur (browser sniffing) (qui vise à déterminer quel est le navigateur qui accède au site). Cette dernière est une mauvaise pratique qui doit être évitée. Voir ci-après Utilisation de mauvais code pour tenter d'identifier le navigateur pour plus de détails.
Note : Nous reviendrons plus en détails sur la détection de fonctionnalités dans un article dédié, dans la suite du module.
Bibliothèques
Les bibliothèques JavaScript sont des composants tiers qu'on peut attacher à une page et qui fournissent des fonctionnalités prêtes à l'emploi, nous évitant d'avoir à les redévelopper. De nombreuses bibliothèques JavaScript ont été créées pour partager des fonctions utilitaires récurrentes et gagner du temps sur l'écrire de future projets.
Il existe différentes variétés de bibliothèques JavaScript (certaines servant à plusieurs choses) :
- Les bibliothèques utilitaires
-
Elles fournissent un ensemble de fonctions pour que les tâches récurrentes soient plus simples et moins ennuyantes à gérer. jQuery des outils de manipulation du DOM (même si ceux-ci sont à mettre en perspective des méthodes natives
Document.querySelector(),Document.querySelectorAll()et de l'interfaceNode. - Les bibliothèques de simplification
-
Elles simplifient certaines tâches complexes. L'API WebGL est par exemple une API très complexe et difficile à manipuler directement « à la main ». C'est pour cela que des bibliothèques Three.js, construites par-dessus WebGL, peuvent s'avérer intéressantes en fournissant une API indirecte, plus simple à manipuler (pour créer des objets 3D, des éclairages, des textures, etc.). De même, l'API Service Worker peut se révéler complexe à utiliser et certaines bibliothèques ont été créées pour simplifier les cas d'usage classiques des service workers (voir le livre de recettes des service worker pour différents exemples).
- Les bibliothèqus d'interface
-
Elles fournissent des méthodes pour implémenter des interfaces utilisateur complexes, qu'il aurait été délicat d'implémenter à partir de 0 et de façon compatible entre les différents navigateurs. On pourra citer Bootstrap, et Material-UI (ce dernier s'utilisant avec le framework React). Ces bibliothèques sont généralement utilisées pour l'intégralité de l'interface utilisateur et il est souvent difficile de les adopter pour implémenter une seule partie de l'interface.
- Les bibliothèques d'abstraction
-
Elles offrent une syntaxe simple qui permet de réaliser une tâche donnée sans avoir à se soucier des différences entre les navigateurs. La bibliothèque s'occupera de manipuler les API adéquates en arrière-plan pour obtenir la fonctionnalité souhaitée (en théorie).
Lors du choix d'une bibliothèque, assurez vous qu'elle fonctionne sur l'ensemble des navigateurs que vous ciblez et testez votre implémentation avec soin. Pour choisir une bibliothèque, il faut aussi vérifier certains critères, comme sa maintenance, sa prise en charge, voire sa popularité, pour éviter une bibliothèque qui devienne obsolète rapidement. N'hésitez pas à échanger avec d'autres personnes pour savoir ce qu'elles utilisent ou recommandent, vérifiez l'activité sur le dépôt de code de la bibliothèque si ses sources sont ouvertes, etc.
Pour utiliser une bibliothèque, il faudra généralement télécharger ses fichiers (JavaScript, parfois CSS et/ou avec d'autres dépendances) et les attacher à la page (par exemple via un élément <script>). D'autres méthodes existent aussi, comme l'installation sous forme de composants Bower ou l'inclusion comme dépendances avec Webpack. Référez vous à la documentation d'installation de chaque bibliothèque pour plus d'informations.
Note : Vous rencontrerez probablement certains frameworks JavaScript comme React, Ember et Angular. Les bibliothèques s'utilisent pour régler différents problèmes et s'intégrer à des sites existants. Les frameworks sont plutôt des solutions complètes pour développer des applications web complexes.
Prothèses d'émulation (polyfills)
Les polyfills sont des fichiers JavaScript tiers que vous pouvez intégrer à votre projet. Ce ne sont pas des bibliothèques qui améliorent des fonctionnalités existantes, mais des prothèses qui permettent d'émuler des fonctionnalités absentes nativement. Les polyfills utilisent JavaScript ou d'autres technologies pour implémenter la fonctionnalité afin de la rendre disponible dans un navigateur qui ne la prend pas en charge. On peut par exemple utiliser des prothèses comme promise-polyfill ou es6-promise pour faire fonctionner les promesses dans les navigateurs qui ne les prennent pas en charge.
Prenons un exemple où nous utiliserons une prothèse pour l'API Fetch et une autre pour les promesses. Bien que ces deux fonctionnalités soient bien prises en charge par les dernières générations de navigateurs, si on souhaite cibler un navigateur plus ancien qui ne prend pas en charge l'API Fetch, il y a de grandes chances qu'il ne soit pas non plus compatible avec les promesses (largement utilisées par l'API Fetch).
-
Pour commencer, téléchargez un exemplaire de
fetch-polyfill.htmlet cette image dans un nouveau répertoire. Nous allons écrire du code pour récupérer cette image et l'afficher sur la page. -
Ensuite, enregistrez une copie de la prothèse d'émulation pour Fetch, dans le même répertoire que le fichier HTML précédent.
-
Appliquez les polyfills à la page en utilisant le code suivant avant l'élément
<script>afin qu'elles soient disponibles sur la page lorsqu'on commence à utiliser l'API Fetch. Nous incluons la prothèse d'émulation des promesses via un CDN :html<script src="https://cdn.jsdelivr.net/npm/es6-promise@4/dist/es6-promise.min.js"></script> <script src="https://cdn.jsdelivr.net/npm/es6-promise@4/dist/es6-promise.auto.min.js"></script> <script src="fetch.js"></script> -
Dans l'élément
<script>qui contient notre script, on ajoute le code suivant :jsconst myImage = document.querySelector(".my-image"); fetch("flowers.jpg").then((response) => { response.blob().then((myBlob) => { const objectURL = URL.createObjectURL(myBlob); myImage.src = objectURL; }); }); -
Si vous chargez alors la page dans un navigateur qui n'est pas compatible avec l'API Fetch, vous devriez néanmoins voir l'image apparaître !

Note : Vous pouvez consulter l'exemple finalisé en ligne (et aussi le code source correspondant).
Note : Il existe différentes façons pour utiliser des prothèses d'émulation. Là encore, référez vous à la documentation de chacune pour en savoir plus.
Mais dans ce cas, pourquoi toujours charger le code du polyfill, même si elle n'est pas nécessaire ? Lorsqu'un site ou une application devient de plus en plus complexe, on peut charger de plus en plus de bibliothèque et de prothèses d'émulation superflues dans certains cas, ce qui pourra avoir un impact sur les performances, notamment sur les appareils ou réseaux les moins puissants. Autant ne charger que les fichiers qui sont nécessaires.
Cela demande une logique supplémentaire dans le code JavaScript. On pourra avoir besoin d'une détection de fonctionnalité qui détermine si le navigateur prend en charge les fonctionnalités voulues :
if (navigateurPrendEnCharge()) {
main();
} else {
chargerScript("polyfills.js", main);
}
function main(err) {
// le code de notre application va ici
}
On commence par un test avec la fonction navigateurPrendEnCharge(). Si ce test renvoie true, on exécute la fonction main() qui contient le code de notre application. La fonction navigateurPrendEnCharge() ressemble à ceci :
function navigateurPrendEnCharge() {
return window.Promise && window.fetch;
}
Nous testons ici si l'objet Promise et si la fonction fetch() existent dans le navigateur. Si c'est le cas pour les deux, la fonction renvoie true. Dans le cas contraire, on exécute le code situé dans l'autre branche conditionnelle, qui appelle la fonction chargerScript(), qui s'occupe de charger les polyfills dans la page avant d'appeler main() lorsque le chargement est terminé. chargerScript() est implémentée ainsi :
function chargerScript(src, done) {
const js = document.createElement("script");
js.src = src;
js.onload = () => {
done();
};
js.onerror = () => {
done(new Error(`Failed to load script ${src}`));
};
document.head.appendChild(js);
}
Cette fonction crée un nouvel élément <script> et renseigne son attribut src avec le chemin que nous lui avons fourni en premier argument (dans notre exemple, nous l'avons appelé avec 'polyfills.js'). Lorsque le script est chargé, on appelle la méthode passée en deuxième argument (main() dans notre exemple avant). Si une erreur se produit lors du chargement du script, on appelle tout de même la fonction, mais avec une erreur personnalisée qui pourra nous aider à diagnostiquer en cas de problème.
Le fichier polyfills.js dont il est question ici correspond à l'assemblage des deux prothèses dans un seul fichier. Nous avons construit ce fichier manuellement, mais sachez qu'il existe d'autres outils pour cela, comme Browserify. Il est généralement utile de fusionner les fichiers JavaScript ensemble pour diminuer le nombre de requêtes HTTP nécessaires et ainsi améliorer les performances d'un site.
Vous pouvez voir le résultat obtenu (et le code source correspondant). Cet exemple a initialement été écrit par Philip Walton, dont le billet Loading Polyfills Only When Needed (en anglais) contient de nombreuses explications à ce propos.
Transpilation JavaScript
Une autre option pour utiliser des fonctionnalités JavaScript récentes consiste à convertir le code dans une version qui fonctionnera pour les anciens navigateurs.
Note : On appelle transpilation cette transformation du code qui ne transforme pas le code dans un langage de plus bas niveau (comme un programme C compilé en binaire), mais qui transforme le code en changeant sa syntaxe avec un même niveau d'abstraction, afin que celui-ci puisse être utilisé dans d'autres circonstances.
Un transpilateur populaire est Babel.js, mais il en existe d'autres.
N'essayez pas de deviner le navigateur
Par le passé, certains sites essayaient de deviner le navigateur utilisé (browser sniffing) pour fournir le code approprié pour ce navigateur.
Tous les navigateurs utilisent une chaîne de caractères user-agent via l'en-tête HTTP User-Agent qui identifie certaines caractéristiques du navigateur (sa version, son nom, le système d'exploitation, etc.). Pour certains sites et applications, le code de détection était incorrect ou n'a pas été maintenu, ce qui a empêché certains navigateurs de les afficher correctement. Ce problème est devenu si fréquent que les navigateurs ont fini par mentir en changeant leur chaîne d'agent utilisateur pour contourner ces mauvaises détections. Les navigateurs ont également mis à disposition des outils permettant aux personnes de modifier par elles-mêmes la chaîne User-Agent, ce qui a fragilisé encore plus les sites et applications qui exploitaient cette chaîne de caractères, voire ce qui a rendu cette technique complètement vaine.
Le billet d'Aaron Anderson, History of the browser user-agent string en anglais, fournit un historique utile voire amusant de cette technique. On privilégiera la détection de fonctionnalité (et @supports en CSS) pour détecter de façon fiable lorsqu'une fonctionnalité donnée est prise en charge. Cette méthode ne nécessite pas de mettre à jour le code lorsque de nouvelles versions des navigateurs sont publiées.
Gestion des préfixes en JavaScript
Dans l'article précédent, nous avons discuté longuement de la gestion des préfixes navigateur en CSS. Pendant un temps, les préfixes étaient également utilisés pour les implémentations de nouvelles fonctionnalités en JavaScript (les préfixes pour JavaScript étaient écrits en camel case et non avec des tirets comme CSS). Par exemple, si un nouvel objet, avec le nom standard Object, était implémenté :
- Firefox aurait utilisé
mozObject - Chrome, Opera, et Safari auraient utilisé
webkitObject - Internet Explorer aurait utilisé
msObject
Voici un exemple, tiré de la démo violent-theremin (voir le code source correspondant), qui utilise l'API Canvas et l'API Web Audio pour créer un outil de dessin un peu bruyant :
const AudioContext = window.AudioContext || window.webkitAudioContext;
const audioCtx = new AudioContext();
Pour l'API Web Audio, le point d'entrée de l'API pour Chrome était préfixé par webkit (les navigateurs basés sur Chromium prennent désormais en charge la version standard sans préfixe). La méthode la plus simple pour contourner le problème consistait à créer une nouvelle version de l'objet en utilisant la version préfixée si la version standard n'était pas disponible.
C'était ensuite cette version de l'objet qui était utilisée pour manipuler l'API plutôt que la version originale. Dans notre exemple, nous avons créé une version modifiée du constructeur AudioContext avant de créer une nouvelle instance de contexte audio à utiliser.
Cette méthode fonctionne pour toutes les fonctionnalités préfixées en JavaScript et peut être utilisée par les bibliothèques et prothèses d'émulation pour rajouter un niveau d'abstraction et simplifier l'hétérogénéité des navigateurs pour la développeuse ou le développeur.
Mais il faut rappeler que les fonctionnalités préfixées n'étaient pas censées être utilisées sur des sites web de production et pouvaient être modifiées voire retirées à tout moment. Utiliser ces versions en production pouvaient donc causer des problèmes de compatibilité entre les navigateurs. Si vous persistez à vouloir utiliser des fonctionnalités préfixées, assurez-vous d'utiliser la bonne version et pour de bonnes raisons. Vous pouvez consulter les pages de référence de MDN et des sites comme caniuse.com pour savoir si les préfixes sont nécessaires. En cas de doute, vous pouvez également tester directement dans un navigateur en ouvrant la console et en tapant le nom de la fonctionnalité voulue : si le navigateur déclenche l'auto-complétion lors de la saisie, cela signifie que la fonctionnalité est présente.
Savoir trouver de l'aide
Vous pourrez tomber sur de nombreux autres problèmes en JavaScript (comme avec tout langage) : le plus important est de savoir comment trouver des réponses en ligne. Voyez la section correspondante de l'article sur HTML et CSS pour nos conseils.