クライアント・サーバーの概要
サーバーサイドプログラミングの目的と潜在的な利点が分かったところで、サーバーがブラウザーから「動的リクエスト」を受け取ったときに起こることを詳細に検討します。ほとんどのウェブサイトのサーバーサイドコードは同様の方法でリクエストとレスポンスを処理するので、これは自身のコードの大部分を書くときに何が必要かを理解するのに役立ちます。
| 前提条件: | ウェブサーバーとは何かについての基本的な理解。 |
|---|---|
| 目的: | 動的なウェブサイトにおけるクライアントとサーバーのやりとり、特にサーバーサイドのコードで実行する必要がある操作を理解すること。 |
まだコードを書くために使用するウェブフレームワークを選んでいないので、この説明には実際のコードはありません。しかし、この説明はとても関連性があるものであり、記述されている動作は、どのプログラミング言語やウェブフレームワークを選択したかにかかわらず、サーバーサイドのコードによって実装されなければならないからです。
ウェブサーバーと HTTP (入門)
ウェブブラウザーはウェブサーバーと、 HTTP (HyperText Transfer Protocol ) を使用して通信します。ウェブページのリンクをクリックしたり、フォームを送信したり、検索を実行したりすると、ブラウザーは HTTP リクエストをサーバーに送信します。
このリクエストに含まれるものは次の通りです。
-
対象のサーバーとリソース (HTML ファイル、サーバー上の特定のデータポイント、実行するツールなど) を識別する URL
-
必要なアクション (たとえば、ファイルを取得したり、データを保存または更新したりするため) を定義するメソッド。さまざまなメソッド/動詞とそれに関連するアクションを以下にリストします。
GET: 特定のリソース (製品に関する情報を含む HTML ファイル、製品のリストなど) を取得します。POST: 新しいリソース (たとえば、新しい記事を Wiki に追加したり、新しい連絡先をデータベースに追加したりします) を作成します。HEAD:GETのように本文を取得せずに、特定のリソースに関するメタデータ情報を取得します。たとえば、リソースが最後に更新された時刻を調べるためにHEADリクエストを使用し、リソースが変更された場合にのみ(より "高価な")GETリクエストを使用します。PUT: 既存のリソースを更新します (または、存在しない場合は新しいリソースを作成します)。DELETE: 指定したリソースを削除します。TRACE,OPTIONS,CONNECT,PATCH: これらの動詞は、あまり一般的ではない高度な作業のためのものなので、ここでは説明しません。
-
追加情報 (たとえば、HTML フォームデータ) をリクエストと共にエンコードすることができます。情報は次のようにエンコードできます。
- URL 引数:
GETリクエストは、サーバーに送信された URL に名前と値のペアを末尾に追加することで、データをエンコードします (例:http://example.com?name=Fred&age=11)。 URL 引数から URL の残りの部分を区切る疑問符 (?)、関連する値から各名前を区切る等号 (=)、および各ペアを区切るアンパサンド (&) が常にあります。URL 引数は、ユーザーが変更して再送信することができるため、本質的に「安全ではありません」。結果として、URL 引数のGETリクエストは、サーバー上のデータを更新するリクエストには使用されません。 POSTデータ:POSTリクエストは新しいリソースを追加し、そのデータはリクエストボディ内にエンコードされます。- クライアントサイド Cookie : Cookie には、クライアントに関するセッションデータが含まれており、サーバーはそれをログイン状態とリソースへの権限/アクセスを判断するために使用できます。
- URL 引数:
ウェブサーバーはクライアントリクエストメッセージを待ち、メッセージが到着したときにそれらを処理し、 HTTP レスポンスメッセージでウェブブラウザーにレスポンスします。レスポンスには、リクエストが成功したかどうかを示す HTTP レスポンスステータスコード (例: 成功した場合は "200 OK"、リソースが見つからない場合は "404 Not Found"、ユーザーがリソースを見ることを許可されていない場合は "403 Forbidden"など)が含まれます。 GET リクエストに対する成功したレスポンスの本文には、リクエストされたリソースが含まれます。
HTML ページが返されると、ウェブブラウザーによってレンダリングされます。 処理の一部として、ブラウザーは他のリソースへのリンクを発見することができ(例えば HTML ページは通常 JavaScript と CSS ページを参照します)、これらのファイルをダウンロードするために別々の HTTP リクエストを送信します。
静的および動的ウェブサイト(以降の節で説明)は、まったく同じ通信プロトコル/パターンを使用しています。
GET リクエスト/レスポンスの例
リンクをクリックするか(検索エンジンのホームページのように)サイトを検索することで簡単な GET リクエストをすることができます。たとえば、MDN で「クライアント - サーバーの概要」という用語を検索したときに送信される HTTP リクエストは、次のようになります(メッセージの一部はあなたのブラウザーや設定に依存するので、同一にはなりません)。
メモ: HTTP メッセージのフォーマットは「ウェブ標準」(RFC7230) で定義されています。このレベルの詳細を知る必要はありませんが、少なくとも今、これら全てがどこから来たのかを知っています!
リクエスト
リクエストの各行にはそれに関する情報が含まれています。 最初の部分はヘッダーと呼ばれ、HTML head に HTML 文書に関する有用な情報が含まれるのと同じで、リクエストに関する有用な情報が含まれます(ただし、実際のコンテンツ自体は含まれません)。
GET /ja/search?q=client+server+overview&topic=apps&topic=html&topic=css&topic=js&topic=api&topic=webdev HTTP/1.1
Host: developer.mozilla.org
Connection: keep-alive
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Referer: https://developer.mozilla.org/ja/
Accept-Encoding: gzip, deflate, sdch, br
Accept-Charset: ISO-8859-1,UTF-8;q=0.7,*;q=0.7
Accept-Language: ja-JP,ja;q=0.8,en;q=0.6
Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; csrftoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT; dwf_section_edit=False; dwf_sg_task_completion=False; _gat=1; _ga=GA1.2.1688886003.1471911953; ffo=true
1 行目と 2 行目には、上記で説明したほとんどの情報が含まれています。
- リクエストのタイプ (
GET) - ターゲットリソースの URL (
/en-US/search) - URL 引数 (
q=client%2Bserver%2Boverview&topic=apps&topic=html&topic=css&topic=js&topic=api&topic=webdev) - ターゲット/ホストのウェブサイト (developer.mozilla.org)
- 最初の行の終わりには、特定のプロトコルバージョンを識別する短い文字列 (
HTTP/1.1) も含まれています。
最後の行にはクライアントサイドの Cookie に関する情報が含まれています。この場合、Cookie にはセッションを管理するための ID (Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; …) が含まれています。
残りの行には、使用されているブラウザーとそれが処理できるレスポンスの種類に関する情報が含まれています。 たとえば、次のようになります。
- 私のブラウザー (
User-Agent) は Mozilla Firefox (Mozilla/5.0) です。 - gzip 圧縮情報 (
Accept-Encoding: gzip) を受け入れることができます。 - 指定された文字セット (
Accept-Charset: ISO-8859-1,UTF-8;q=0.7,*;q=0.7) および言語 (Accept-Language: ja-JP,ja;q=0.8,en;q=0.6) を受け入れることができます。 Referer行は、このリソースへのリンク (つまり、リクエストの発信元、https://developer.mozilla.org/en-US/) を含んだウェブページのアドレスを示します。
HTTP リクエストも本文を持つことができますが、この場合は空です。
レスポンス
このリクエストに対するレスポンスの最初の部分を以下に示します。ヘッダーには、次のような情報が含まれています。
- 最初の行にはレスポンスコード
200 OKが含まれています。これはリクエストが成功したことを示しています。 - レスポンスが
text/htmlフォーマットの (Content-Type) であることがわかります。 - また、UTF-8 文字セット(
Content-Type: text/html; charset=utf-8) が使用されていることもわかります。 - ヘッダーはそれがどれくらい大きいかも教えてくれます (
Content-Length: 41823)。
メッセージの最後に本文があります。これにはリクエストによって返された実際の HTML が含まれています。
HTTP/1.1 200 OK
Server: Apache
X-Backend-Server: developer1.webapp.scl3.mozilla.com
Vary: Accept, Cookie, Accept-Encoding
Content-Type: text/html; charset=utf-8
Date: Wed, 07 Sep 2016 00:11:31 GMT
Keep-Alive: timeout=5, max=999
Connection: Keep-Alive
X-Frame-Options: DENY
Allow: GET
X-Cache-Info: caching
Content-Length: 41823
<!DOCTYPE html>
<html lang="ja" dir="ltr" class="redesign no-js" data-ffo-opensanslight=false data-ffo-opensans=false >
<head prefix="og: http://ogp.me/ns#">
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<script>(function(d) { d.className = d.className.replace(/\bno-js/, ''); })(document.documentElement);</script>
…
レスポンスヘッダーの残りの部分には、レスポンス (たとえば、いつ生成されたか)、サーバー、およびブラウザーがページを処理する方法についての情報が含まれます (たとえば、X-Frame-Options: DENY 行は、このページを別のサイトの <iframe> に埋め込むことを許可しないようにブラウザーに指示します)。
POST リクエスト/レスポンス 例
HTTP POST は、サーバーに保存する情報を含むフォームを送信したときに作成されます。
リクエスト
以下のテキストは、ユーザーがこのサイトに新しいプロファイルの詳細を送信したときに行われる HTTP リクエストを示しています。最初の行はこのリクエストを POST として識別しますが、リクエストのフォーマットは前述の GET リクエストの例とほぼ同じです。
POST /ja/profiles/hamishwillee/edit HTTP/1.1
Host: developer.mozilla.org
Connection: keep-alive
Content-Length: 432
Pragma: no-cache
Cache-Control: no-cache
Origin: https://developer.mozilla.org
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Referer: https://developer.mozilla.org/en-US/profiles/hamishwillee/edit
Accept-Encoding: gzip, deflate, br
Accept-Language: en-US,en;q=0.8,es;q=0.6
Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; _gat=1; csrftoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT; dwf_section_edit=False; dwf_sg_task_completion=False; _ga=GA1.2.1688886003.1471911953; ffo=true
csrfmiddlewaretoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT&user-username=hamishwillee&user-fullname=Hamish+Willee&user-title=&user-organization=&user-location=Australia&user-locale=en-US&user-timezone=Australia%2FMelbourne&user-irc_nickname=&user-interests=&user-expertise=&user-twitter_url=&user-stackoverflow_url=&user-linkedin_url=&user-mozillians_url=&user-facebook_url=
主な違いは URL に引数がないことです。ご覧のとおり、フォームからの情報はリクエストの本文にエンコードされています (たとえば、新しいユーザーの fullname は &user-fullname=Hamish+Willee を使用して設定されます)。
レスポンス
リクエストからのレスポンスは以下のとおりです。ステータスコード "302 Found" は、投稿が成功したこと、および Location フィールドで指定されたページを読み込むために 2 番目の HTTP リクエストを発行する必要があることをブラウザーに通知します。その他の点では、この情報は GET リクエストへのレスポンスに関する情報と似ています。
HTTP/1.1 302 FOUND
Server: Apache
X-Backend-Server: developer3.webapp.scl3.mozilla.com
Vary: Cookie
Vary: Accept-Encoding
Content-Type: text/html; charset=utf-8
Date: Wed, 07 Sep 2016 00:38:13 GMT
Location: https://developer.mozilla.org/en-US/profiles/hamishwillee
Keep-Alive: timeout=5, max=1000
Connection: Keep-Alive
X-Frame-Options: DENY
X-Cache-Info: not cacheable; request wasn't a GET or HEAD
Content-Length: 0
メモ: これらの例に示されている HTTP レスポンスとリクエストは Fiddler アプリケーションを使ってキャプチャされました。しかし、ウェブスニファー(WebSniffer など)や、パケットアナライザー(Wireshark)などを使って同様の情報を得ることができます。これは自分で試すことができます。リンクされているツールを使用してから、サイト内を移動してプロファイル情報を編集し、さまざまなリクエストとレスポンスを確認します。最近のほとんどのブラウザーには、ネットワークリクエストを監視するツール(たとえば、Firefox のネットワークモニタツール)もあります。
静的サイト
静的サイトは、特定のリソースがリクエストされたときはいつでもサーバーから同じハードコードされたコンテンツを返すものです。たとえば、製品に関するページが /static/myproduct1.html にある場合、この同じページがすべてのユーザーに返されます。サイトに他の似たような製品を追加するならば、別のページ (例えば myproduct2.html) を追加する必要があるでしょう。これは本当に非効率的になり始めます — 何千もの製品ページにたどり着くとどうなるでしょう? 各ページ (基本的なページテンプレート、構造など) に渡って多くのコードを繰り返すことになります。ページ構造について何か変更したい場合 (たとえば、新しい「関連商品」セクションを追加するなど) 各ページを個別に変更する必要があります。
メモ: ページ数が少なく、すべてのユーザーに同じコンテンツを送信したい場合は、静的サイトが優れています。ただし、ページ数が増えると、管理に多大なコストがかかる可能性があります。
前回の記事で見た静的サイトのアーキテクチャ図をもう一度見て、これがどのように機能するのかを要約しましょう。
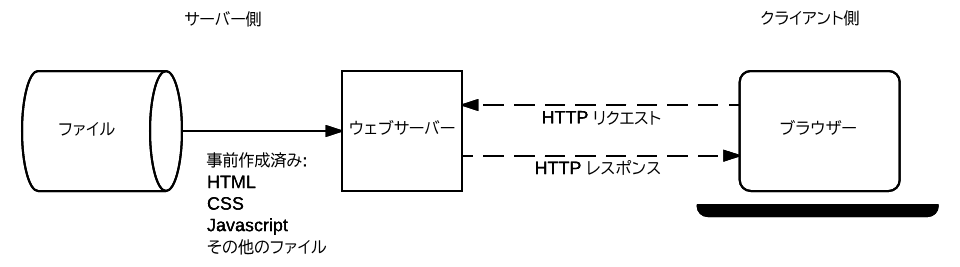
ユーザーがページに移動したい場合、ブラウザーはその HTML ページの URL を指定した HTTP GET リクエストを送信します。サーバーはファイルシステムからリクエストされた文書を検索し、その文書と "200 OK" の HTTP レスポンスステータスコード (成功を示す)を含む HTTP レスポンスを返します。ファイルがサーバーに存在しない場合は "404 Not Found"、ファイルが存在するが別の場所にリダイレクトされている場合は "301 Moved Permanently" など、サーバーは別のステータスコードを返すことがあります。
静的サイトのサーバーは可変データを格納しないため、 GET リクエストを処理するだけで済みます。また、HTTP リクエストデータ(URL 引数やクッキーなど)に基づいてレスポンスを変更することもありません。
それでも、動的サイトは静的ファイル(CSS、JavaScript、静的な画像など)に対するリクエストをまったく同じ方法で処理するため、静的サイトの機能を理解することはサーバーサイドプログラミングを学ぶときに役立ちます。
動的サイト
動的サイトとは、特定のリクエスト URL とデータに基づいてコンテンツを生成して返すことができる(特定の URL に対して常に同じハードコードされたファイルを返すのではない)サイトです。製品サイトの例を使用すると、サーバーは個々の HTML ファイルではなくデータベースに製品の「データ」を保管します。製品の HTTP GET リクエストを受信すると、サーバーは製品 ID を決定し、データベースからデータを取得してから、そのデータを HTML テンプレートに挿入することによって、レスポンス用の HTML ページを作成します。これは静的サイトよりも大きな利点があります。
データベースを使用すると、製品情報を簡単に拡張、変更、および検索可能な方法で効率的に格納できます。
HTML テンプレートを使用すると、HTML 構造の変更が非常に簡単になります。これは 1 つの場所、1 つのテンプレート内で行う必要があるだけで、潜在的に何千もの静的ページでは行わないためです。
動的リクエストの構造
このセクションでは、前回の記事で説明した内容に基づいて、「動的な」HTTP リクエストとレスポンスのサイクルの概要を段階的に説明します。"物事を現実のものにする" ために、コーチが HTML 形式で彼らのチーム名とチームサイズを選択して、彼らの次のゲームのために提案された "最高のラインナップ" を取り戻すことができるスポーツチームマネージャーウェブサイトのコンテキストを使います。
以下の図は、「チームコーチ」ウェブサイトの主な要素と、コーチが「ベストチーム」リストにアクセスしたときの一連の操作の番号付きラベルを示しています。サイトの一部は ウェブアプリケーション (これは HTTP リクエストを処理し、HTTP レスポンスを返すサーバーサイドコードを指す方法です)、データベース、これにはプレイヤー、チーム、コーチ、そして彼らの関係についての情報が含まれています、そして HTML テンプレートです。
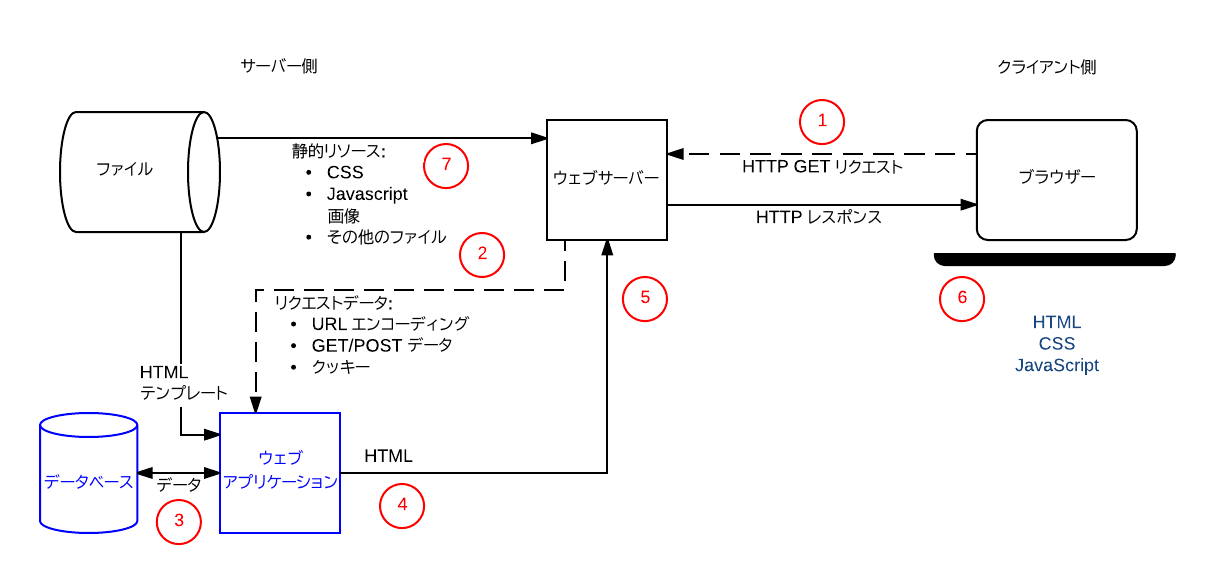
コーチがチーム名と選手の数を記入したフォームを送信した後、一連の操作は次のようになります。
- ウェブブラウザーはリソースのベース URL (
/best) を使用し、URL 引数 (例:/best?team=my_team_name&show=11) または URL パターンの一部 (例:/best/my_team_name/11/) としてチームと選手の番号をエンコードしたものを使用して、サーバーへの HTTPGETリクエストを作成します。GETリクエストが使用されるのは、リクエストがデータをフェッチするだけである (データを変更しない) ためです。 - ウェブサーバーはリクエストが「動的」であることを検出し、それを処理 (ウェブサーバーは、その構成で定義されたパターンマッチング規則に基づいてさまざまな URL を処理する方法を決定します) のために ウェブアプリケーションに転送します。
- ウェブアプリケーションは、リクエストの意図が URL (
/best/) に基づいて「最善のチームリスト」を取得することであることを識別し、URL から必要なチーム名とプレーヤーの数を見つけます。その後、ウェブアプリケーションはデータベースから必要な情報を取得します (どのプレーヤーが「最高」であるかを定義するために追加の「内部」引数を使用し、クライアント側の Cookie からログインしたコーチの身元も取得する可能性があります)。 - ウェブアプリケーションは、(データベースからの) データを HTML テンプレート内のプレースホルダに入れることで、HTML ページを動的に作成します。
- ウェブアプリケーションは、生成された HTML を HTTP ステータスコード 200 ("成功") とともに(ウェブサーバー経由で)ウェブブラウザーに返します。HTML が返されるのを妨げるものがあると、ウェブアプリケーションは別のコードを返します。たとえば、"404" はチームが存在しないことを示します。
- ウェブブラウザーは返された HTML の処理を開始し、それが参照する他の CSS または JavaScript ファイルを取得するための個別のリクエストを送信します (手順 7 を参照)。
- ウェブサーバーはファイルシステムから静的ファイルをロードして直接ブラウザーに返します (これも正しいファイル処理は設定ルールと URL パターンマッチングに基づいています)。
データベース内のレコードを更新する操作も同様に処理されます。データベースの更新と同じですが、ブラウザーからの HTTP リクエストは POST リクエストとしてエンコードされるはずです。
他の仕事をする
ウェブアプリケーションの仕事は、HTTP リクエストを受信し、HTTP レスポンスを返すことです。情報を取得または更新するためにデータベースと相互にやり取りすることは非常に一般的な作業ですが、コードは同時に他のことを実行することも、データベースとやり取りしないこともあります。
ウェブアプリケーションが実行する追加のタスクの良い例は、ユーザーにメールを送信してサイトへの登録を確認することです。サイトはロギングやその他の操作も実行する可能性があります。
HTML 以外のものを返す
サーバーサイドのウェブサイトのコードは、レスポンスに HTML スニペット/ファイルを返す必要はありません。代わりに動的に他の種類のファイル (テキスト、PDF、CSV など) あるいはデータ (JSON、XML など) を作成して返すことができます。
これは特に、新しいコンテンツを表示させるときに常に新しいページを読み込むのではなく、 JavaScript を使用してサーバーからコンテンツを取得して動的にページを更新して作業するウェブサイトにとって有益なことです。この手法の動機や、このモデルがクライアントから見てどのように見えるかについては、サーバからのデータの取得を参照してください。
ウェブフレームワークはサーバーサイドのウェブプログラミングを簡素化する
サーバーサイドウェブフレームワークにより、上記の操作を処理するコードを非常に簡単に書くことができます。
それらが実行する最も重要な操作の 1 つは、異なるリソース/ページの URL を特定のハンドラー関数にマッピングするための単純なメカニズムを提供することです。これにより、各タイプのリソースに関連付けられているコードを別々にしておくことが容易になります。また、ハンドラー機能を変更することなく、特定の機能を提供するために使用される URL を 1 か所で変更できるため、メンテナンスの面でもメリットがあります。
たとえば、2 つの URL パターンを 2 つのビュー関数にマップする次の Django (Python) コードを考えてみましょう。最初のパターンは、/best のリソース URL を持つ HTTP リクエストが views モジュールの index() という名前の関数に渡されることを保証します。パターン "/best/junior" を持つリクエストは、代わりに junior() ビュー関数に渡されます。
# file: best/urls.py
#
from django.conf.urls import url
from . import views
urlpatterns = [
# example: /best/
url(r'^$', views.index),
# example: /best/junior/
url(r'^junior/$', views.junior),
]
メモ: url() 関数の最初の引数は、「正規表現」(RegEx, または RE) と呼ばれるパターンマッチング手法を使用するため、少し奇妙に見える (たとえば、r'^junior/$') ことがあります。この時点で正規表現がどのように機能するのかを知る必要はありませんが、(上のハードコードされた値ではなく) URL のパターンと一致させてビュー関数の引数として使用できるという点が異なります。例として、非常に単純な正規表現は、「1 つの大文字に一致し、その後に 4〜7 つの小文字を一致させる」と言うかもしれません。
ウェブフレームワークはまた、ビュー関数がデータベースから情報を取得するのを容易にします。データの構造はモデルで定義されています。これは基礎となるデータベースに格納されるフィールドを定義する Python クラスです。"team_type" のフィールドを持つ Team というモデルがある場合は、単純なクエリー構文を使用して特定のタイプを持つすべてのチームを取り戻すことができます。
以下の例では、 "大文字と小文字を区別する" 正確な team_type が "junior" であるすべてのチームのリストを取得します — フォーマットに注意してください。フィールド名 (team_type) の後に二重下線、そして使用する一致のタイプ (この場合は exact) です。他にもたくさんの種類の一致があり、それらをデイジーチェーンでつなげることができます。 順序と返される結果の数も制御できます。
#best/views.py
from django.shortcuts import render
from .models import Team
def junior(request):
list_teams = Team.objects.filter(team_type__exact="junior")
context = {'list': list_teams}
return render(request, 'best/index.html', context)
junior() 関数は、ジュニアチームのリストを取得した後、render() 関数を呼び出して、元の HttpRequest、HTML テンプレート、およびテンプレートに含める情報を定義する "context" オブジェクトを渡します。render() 関数は、コンテキストと HTML テンプレートを使用して HTML を生成し、それを HttpResponse オブジェクトに返す便利な関数です。
明らかにウェブフレームワークは他にも多くのタスクで役に立ちます。次の記事では、さらに多くの利点といくつかの一般的なウェブフレームワークの選択について説明します。